El enriquecimiento de contenidos ha sido la apuesta más fuerte de nuestra empresa por una línea de innovación. Por eso este servicio apenas tiene competencia y también por eso ha sido especialmente difícil despertar la necesidad en algunas ocasiones. La ventaja es que el enriquecimiento de prensa digital, entendida como la capacidad para aportar al lector contenido relevante en el momento oportuno, también puede ser extrapolada a otros sectores, como la televisión (Smart TV, EPG, Second Screen) y el sector editorial (ebooks y libros de papel) e incluso la realidad aumentada. En general, siempre que haya un texto digital es posible aplicar el servicio de Classora para obtener información adicional, y programar sus robots para que la actualicen con la cadencia necesaria para satisfacer las demandas del producto.

En este sentido, Classora es una de las pocas empresas que puede proporcionar un servicio que permita detectar, de manera automática, todas aquellas entidades de las que se puede proporcionar información útil al televidente, especialmente en productos diferidos (películas, series, documentales). El usuario puede entonces decidir qué información adicional visualiza acompañando al programa actual: datos enciclopédicos, galerías de imágenes, mensajes relacionados en redes sociales, mapas, clasificaciones deportivas… etc. Esta información adicional puede ser consumida directamente en la pantalla del televisor o en dispositivos de second screen (tablets… etc.). Este servicio fue desarrollado inicialmente con el departamento de I+D de Grupo Prisa, y continuado posteriormente con CINFO (compañía participada por R Cable y Comunicaciones).
Desde el punto de vista técnico, solo es necesario disponer como entrada un fichero de subtítulos, en formato SRT, de una película o serie de TV. Tras un procesado semántico, el servicio devuelve como salida un fichero XML/JSON/HTML con información enriquecida de la película/serie, incluyendo personajes, lugares y empresas que se mencionan durante los diálogos.
El enriquecimiento proporcionado por este servicio puede conseguir unos resultados óptimos debido a que, al tratarse de productos diferidos, los textos y diálogos se conocen de antemano, y por tanto es posible realizar un procesado semántico exhaustivo (no limitado por las exigencias de tiempo real). Una vez procesada una película o serie, el fichero de enriquecimiento queda asociado a ella y es posible que sea reutilizado todas las ocasiones que resulte necesario.
La gran ventaja que ofrece este servicio, aparte del valor añadido para el usuario, que permite mantener el share, es la explotación publicitaria en segunda pantalla.
Como en otras ocasiones, si te interesa conocer más información sobre este servicio no dudes en contactar con nosotros para que te enviemos documentación adicional. Cuenta con Classora Technologies para estar informado sobre Big Data y Data-Driven Journalism.
La integración del concepto Big Data dentro del mundo de los medios y, también, la explotación del conocimiento encerrado en los datos es una de las principales herramientas con la que cuentan los periódicos para desarrollar su negocio digital y por ende para garantizar su supervivencia en la nueva realidad que vivimos, producto de la eclosión definitiva de Internet, especialmente en las nuevas formas de consumir y acceder a la información que tiene la audiencia.
Por otra parte, según declaran los principales gurús del mundo del Big Data, para explotar adecuadamente el potencial que ofrecen la data, es imprescindible que las organizaciones integren en sus equipos humanos la figura del Científico de Datos, también conocidos como Data Scientist.

Pero para poder entender mejor esta nueva figura y el valor que puede tener para los medios, me he dirigido a mi buen amigo, experto del mundo de los datos y profundo conocedor de las organizaciones periodísticas, Francisco Vásquez, CEO y fundador de Audience Circles, para plantearle las siguientes cuestiones:
El Científico de Datos (Data Scientist) es una mezcla híbrida de varios talentos y destrezas. No necesita un título académico en Estadística, Ciencias de la Computación o Administración de Empresas. Pero si necesita un conocimiento básico de cómo funcionan los modelos predictivos de la estadística inferencial y del manejo de paquetes estadísticos como SAS, SPSS o R; requiere de una comprensión de los lenguajes de computación como C++, JavaScript, Python, Perl y otros; necesita una visión global de marketing y de cómo la inteligencia de negocios puede mejorar la ventaja competitiva de una empresa con el conocimiento cabal de los deseos, gustos y preferencias de sus clientes. Todas estas habilidades, con una buena dosis de sentido común, convertirán a cualquier persona en el científico ideal para cualquier empresa.
En general el analista tradicional no tiene formación en computación o estadística. A lo sumo, tuvo que tomar un curso en cada una de esas áreas. Sin embargo, puede llegar a dirigir a un equipo de estadísticos y técnicos para realizar las tareas.
Su principal valor para el medio es que ha podido integrar al personal del departamento de computación con el departamento comercial. El Data Scientist, tiene que entenderse con los dos lados y debe aprenderse el discurso y la jerga de ambas y los temas que para ellas son prioritarios.

La oportunidad para los medios está en poder integrar datos de web analytics, registro de usuarios y encuestas en una base de de datos común, para poder extraer de ahí todos los insights sobre el comportamiento de sus usuarios en el consumo del contenido y en actividades de búsqueda de información sobre productos y servicios… y de este modo optimizar los anuncios, banners que aparezcan en el sitio web.
Artículo original publicado por Ángel Leo-Revilla en su blog Momento TIC.
Classora Technologies ha estado de mudanza este mes en La Coruña. Por suerte, nos hemos trasladado a una oficina más grande, moderna y próxima al centro de la ciudad. Atrás hemos dejado muchos recuerdos y momentos inolvidables en la anterior oficina, la que considerábamos nuestro «garaje» particular, el sitio donde empezó todo. Han pasado muchas cosas desde entonces y ahora debemos adaptarnos a la nueva situación, así que a partir de hoy podéis encontrarnos en:
Classora Technologies S.L.
Calle Novoa Santos 6 – 8, 1º
15006 A Coruña
")
El teléfono y los demás datos de contacto no han variado, al igual que la ubicación física de la oficina en Lugo. De modo que quedamos a vuestra disposición a través de los medios de siempre.
El informe “The Information Generation: Transforming The Future, Today” elaborado por Institute for the Future para EMC, y presentado en estos días, llega a la conclusión de que una de cada dos empresas reconoce abiertamente que no sabe cómo sacarle provecho a los datos que manejan.

Está ampliamente aceptado que la huella digital de personas y las cosas en Internet es un activo para el desarrollo de nuevas iniciativas de negocios. Cada vez más, las personas, están conectadas de manera constante: aprendiendo, jugando, comprando por Internet o viendo la televisión; y, por lo tanto plantean nuevas demandas digitales a las organizaciones con las que interactúan. Pero, sin embargo, son muy pocas las empresas que están efectivamente explotando las oportunidades que se les presentan.
Según la consultora Gartner, en el año 2020, se estima que cada habitante de la Tierra tendrá una media de 5 dispositivos conectados. Todos estos dispositivos, según datos de IDC, habrán generado la friolera de 44 zettabytes de datos, lo que en una medida más mundana que todos más o menos podamos entender, serían unos 10.000 millones de DVDs.
Sin embargo, a pesar de que las empresas son conscientes que pueden obtener un gran valor de esta información, las expectativas que reflejan el estudio presentado por EMC, desvelan que las empresas no terminan de aplicar unas estrategias adecuadas:
Dentro del mismo informe, se han identificado cinco capacidades empresariales que marcarán la diferencia entre el éxito y el fracaso para las organizaciones, ante el desafío del manejo de grandes volúmenes de datos:
Según declaró, David Goulden, CEO de la división de Infraestructuras de la Información de EMC, durante la presentación del estudio: “Las empresas ‘nacidas de la nube’, están impulsando un cambio en las expectativas, y las empresas más maduras se deben plantear su transformación, para adaptarse y seguir siendo relevantes en el mundo digital”.
Y los usuarios ¿qué pasa con ellos?, para el 96% de los encuestados, que participaron en el estudio, las nuevas tecnologías “han cambiado para siempre las reglas del juego en el mundo empresarial”, empezando por las expectativas de los clientes. Ahora demandan cada vez más una mejor conectividad y acceso a los servicios, que tienen que ser, a su vez, más personalizados.
Artículo original publicado por Ángel Leo-Revilla en su blog Momento TIC.
En esta entrada vamos a hacer un repaso rápido del funcionamiento general de la publicidad en Internet, empezando por conceptos básicos, como los tipos de publicidad y los modelos de pago más usuales, y siguiendo hasta tratar conceptos más avanzados, como el último software disponible para gestionar la publicidad programática. No es nuestra intención crear un manual detallado, sino hacer un resumen sucinto y útil de cómo es el mecanismo que rige hoy en día el negocio de la publicidad en Internet.
Tradicionalmente, en la publicidad en Internet había tres actores: anunciantes (o agencias), editores (también llamados soportes o publishers) y usuarios. El anunciante pagaba al editor cada vez que el usuario veía o hacía click en un anuncio. Las operaciones solían basarse en los siguientes modelos de pricing:
Si bien existen muchos tipos de publicidad en la Red, por hacer una clasificación práctica se pueden distinguir las siguientes categorías:
El inventario es el espacio publicitario que tenemos disponible en nuestra web para insertar anuncios en un momento dado. Sin embargo, para entender el concepto práctico de inventario es importante no limitar esta definición a una única dimensión: el espacio, ya que entra en juego otra dimensión igual de importante: el tiempo. Y es que gestionar el inventario teniendo en cuenta los huecos disponibles para una campaña en un momento dado es algo complejo, especialmente porque un determinado espacio puede estar ocupado por una campaña:
Si delegamos la publicidad de nuestra web en una red de anuncios (una Ad Network como AdSense o Infolinks) la gestión del inventario ya la realiza automáticamente la red. Sin embargo, si deseamos vender directamente nuestro inventario a potenciales anunciantes, o si queremos que diferentes redes de anuncios compitan entre sí, para maximizar beneficios, entonces es necesario utilizar un Ad Server (Google DFP, Atlas, Open X, SmartAdServer… etc.).
De esta forma, un diario digital puede vender su banner superior a una determinada empresa mediante una campaña como las que se han indicado antes.
Visto desde la otra perspectiva, una agencia de publicidad puede contactar con A3Media y Mediaset para incrustar anuncios televisivos, y con El País y el Mundo para contratar su inventario y poner el banner superior.
Y hasta aquí la publicidad tradicional.
Gracias a la publicidad programática, las agencias tienen la oportunidad de definir las audiencias (target) a las que van dirigidos sus anuncios en la web. Y ese target lo introducen en los Ad Exchanges. Por ejemplo, indican que su campaña va dirigida a hombres de entre 25 y 35 años del norte de España, que lean El Pais o El Mundo. Es decir, no contratan el inventario de El País para poner su banner de manera indiscriminada, sino que su banner solamente aparece si el usuario coincide con el perfil que está buscando. Dicho de otra forma: la plataforma decide en tiempo real que anuncio se muestra en cada navegador de cada usuario que esté leyendo El Pais. Lo que implica que dos personas diferentes que estén visualizando ese periódico al mismo tiempo pueden recibir un anuncio diferente.
Esto también se podía hacer de cierto modo en las Ad Networks tradicionales, como AdSense: diferentes anunciantes podían contratar de manera transversal a varios editores. Y diferentes editores podían incorporar de manera transversal diferentes anunciantes. Sin embargo, los Ad Exchanges añaden una mayor transparencia y flexibilidad al proceso.
Estas son los puntos diferenciales a tener en cuenta:
Al igual que en los Ad Networks, puede suceder que existan varias campañas que vayan dirigidas al mismo perfil de personas, o al menos, a perfiles que se solapen. Por ejemplo, una campaña que vaya dirigida a hombres y mujeres de toda España que tengan más de 20 años se solapará con la campaña anterior (hombres de entre 25 y 35 años). En este caso, para decidir quien se lleva el inventario de El País es necesario hacer una subasta: la campaña que esté dispuesta a pagar el precio más alto en un momento dado para un determinado perfil de lector se llevará el inventario sobre el que imprimir sus anuncios. Estas pujas en tiempo real se llaman RTB (Real Time Bidding) y dan lugar a una especie de mercado continuo, o bolsa, donde la cotización de un determinado inventario varía en función de la demanda. Es decir, el precio del banner superior que muestra El País depende de 1) las campañas activas y, en consecuencia: 2) del día y la hora 3) del perfil de las personas que se conecte en cada momento.
Por supuesto, no hay una persona que esté todo el rato vigilando el Ad Exchange para decidir cuando pujar. Existe un software denominado DSP (Demand Side Platform) que está destinado para que los anunciantes y las agencias interactúen con los Ad Exchanges. En un DSP se pueden especificar los perfiles a los que van destinadas las campañas, así como una serie de parámetros adicionales que sirven para configurar la política de pujas, es decir, el RTB.
Desde el punto de vista de un editor (publisher), con la publicidad programática es complicado gestionar el inventario: rellenar los huecos con publicidad en función del momento del día y del perfil de usuario que nos visite. Es necesario hacer estimaciones, análisis predictivos… etc. De hecho, si en programática vendes más inventario del que puedes proporcionar, te pueden multar con una penalización. Y al contrario, puede que al final del día te quede inventario invendido, que hay que rellenar con Ad Networks u otros anunciantes menos rentables.

Como en otras ocasiones, si te interesa conocer más información sobre este tema no dudes en contactar con nosotros para que te enviemos documentación adicional. Cuenta con Classora Technologies para estar informado sobre publicidad en Internet.
Reproducimos a continuación un texto de Ángel Leo-Revilla, gran profesional en la consultoría de medios, que trata acerca de cómo deben medir su influencia los medios editoriales en el mundo digital.
El nuevo escenario digital ha supuesto un radical vuelco en la forma en que los medios miden su influencia en las audiencias. Antes, esta influencia, se basaban en una cuantificación, más o menos acertada, del alcance que tenían sus publicaciones mediante la agregación de, por un lado, el número de ediciones que ponían en circulación multiplicado por el supuesto número de personas que leían cada ejemplar y, por el otro, del número de menciones que en otros medios se hacían de sus contenidos publicados.
Sin embargo, en el ecosistema digital, los medios editoriales cuentan con una serie de elementos que les permiten profundizar de una manera más fehaciente en su verdadera influencia frente a las audiencias.
Para medir su influencia en el mundo digital, es clave para los medios editoriales:

Obviamente para realizar bien este trabajo es indispensable contar con soluciones que les permitan integrar en un solo panel de control sus distintas herramientas de medición y análisis, de manera que dispongan de información precisa en todo momento y puedan ser ágiles en su toma de decisiones.
La última edición del TEDxGalicia tuvo lugar en Enero de 2015 en Carballo, y en ella nuestro compañero Iván Gómez participó como ponente ofreciendo una charla acerca de su experiencia en Classora Technologies y en las otras empresas en las que ha desarrollado su carrera profesional. La exposición de Iván trató del conocimiento y el poder que se puede extraer de los datos si los manipulamos con las herramientas adecuadas, utilizando por ejemplo las últimas técnicas de Big Data, Business Intelligence o Data Mining. En su discurso Iván también describió la relación entre diferentes conceptos de actualidad vinculados con los datos, como el Big Data, el Linked Data y el Open Data.
La carrera profesional de Iván estuvo ligada desde siempre al análisis de datos en ámbitos tan diversos como la imagen médica (angiografías digitales de retina sobre las que detectar y medir automáticamente venas y arterias), la inteligencia empresarial (ha sido consultor en Business Intelligence, aplicando técnicas de minería de datos para encontrar patrones complejos en la información) y las tecnologías semánticas (tratando de sintetizar automáticamente la información subyacente en textos desestructurados).
En Classora Technologies ha participado activamente en el desarrollo de una tecnología puntera basada en la extracción, integración, modelado y visualización de datos procedentes de múltiples fuentes. El objetivo es dotar a los medios de tecnologías semánticas y de un fondo documental inédito que les permita incrementar sus indicadores de tráfico, agilizar procesos, fomentar la reutilización de contenidos, maximizar presencia en motores de búsqueda y mejorar la experiencia de usuario.
Classora Technologies atesora la mayor base de conocimiento en español por volumen de información estructurada: más de dos millones de fichas de personas, empresas, lugares… miles de informes, mapas y gráficas, y cientos de millones de análisis comparativos potenciales. Toda la información se encuentra constantemente monitorizada por los robots de carga de Classora en las fuentes de datos oficiales.

TED (Technology, Entertainment, Design) es una organización sin ánimo de lucro dedicada difundir ideas que merece la pena compartir. De hecho, su slogan es precisamente: Ideas worth spreading. Esta organización es ampliamente conocida por su congreso anual (TED Conference) y sus charlas (TED Talks) que cubren un amplio espectro de temas que incluyen ciencias, arte y diseño, política, educación, cultura, negocios, asuntos globales, tecnología y entretenimiento. Entre los conferenciantes se cuentan personas como Bill Clinton, Bill Gates, o los fundadores de Google Sergey Brin y Larry Page.
TEDxGalicia, al igual que todos los eventos TEDx, es organizado de manera independiente con una licencia TED. Los eventos TEDx no tienen ánimo de lucro, pero pueden cobrar la entrada o buscar patrocinadores para cubrir costes. Los conferenciantes deben renunciar a los derechos de copyright por los materiales generados, para que TED pueda editarlos y distribuirlos bajo una licencia Creative Commons.
Hay más de 1.000 charlas TED y TEDx publicadas para consulta y descarga gratuita. Las charlas disponibles han sido vistas más de 500 millones de veces y han sido traducidas a más de 80 idiomas.
Todas las charlas de esta edición de TEDxGalicia están disponibles en el canal oficial TEDx Talks en Youtube.
El Instituto Nacional de Estadística (INE) realizó en el año 2011 la operación de recopilación de datos más cara del Estado: el censo demográfico y de viviendas de todo el país. Esta operación, que además es la de mayor tradición en la historia de la entidad, supone un esfuerzo tan importante que solo se realiza una vez cada 10 años.
La estructuración y el análisis de esos datos suponen otra costosa batalla a la que se tienen que enfrentar los responsables de la operación. Debido al ingente volumen de datos a estudiar, pasan meses, e incluso años, hasta que se pueden publicar informes contrastados que contienen los resultados.
En este sentido, una de las publicaciones que se ha dado a conocer últimamente es un espectacular informe que contiene 25 mapas que desglosan la realidad demográfica española a nivel de kilómetro cuadrado. Es la primera vez en la historia que se pueden analizar los datos censales de manera independiente a los límites administrativos (municipios, distritos, provincias… etc.)

Toda esta información está publicada en la web del INE. A continuación mostraremos algunos ejemplos de mapas relevantes o curiosos, con los enlaces a la web original del Instituto Nacional de Estadística para los que deseen profundizar en la información.
El mapa permite diferenciar claramente las grandes ciudades y zonas metropolitanas, aunque gracias a su grado de detalle también se pueden localizar otras zonas densamente pobladas y no necesariamente asociadas una gran urbe, especialmente en el noroeste peninsular.
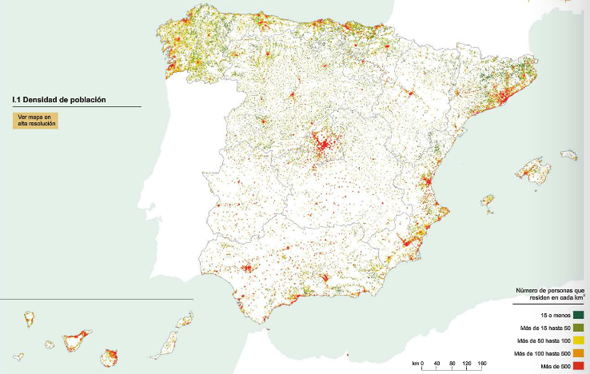
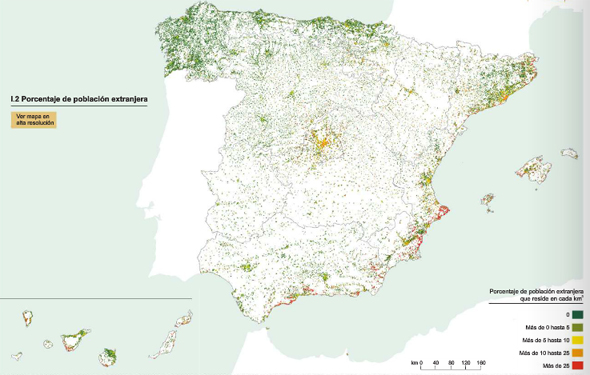
En general, Madrid, Barcelona y los municipios costeros del sur y del este de España, así como las islas, concentran los porcentajes más elevados de extranjeros.
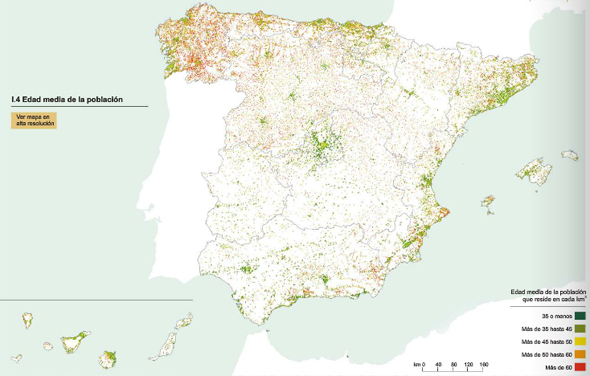
En el mapa se aprecia como, en términos generales, la edad media de las celdas situadas en el sur de España es menor que el de las celdas situadas en el norte.
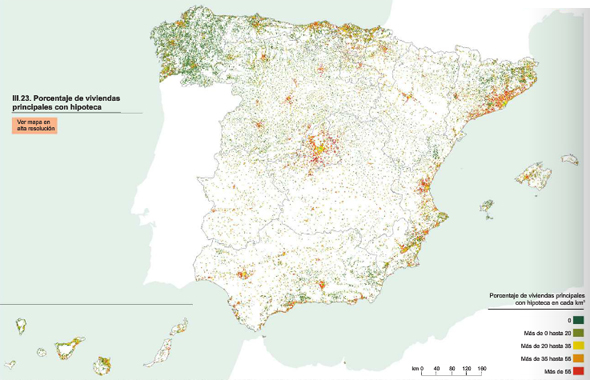
Los porcentajes más elevados de hipotecas se encuentran en los alrededores de los núcleos urbanos. En términos generales, también existe un predominio de nuevas hipotecas en el sur frente al norte.
Se aprecia una diferencia entre la superficie de las viviendas en las ciudades y en medio rural. También se pueden distinguir ciertas características entre norte y sur.
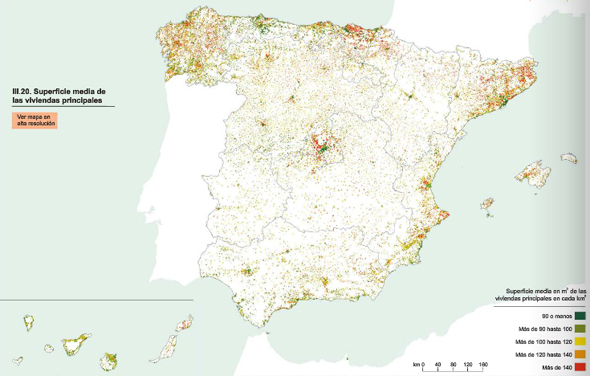
Como en otras ocasiones, si te interesa conocer más información sobre este tema no dudes en contactar directamente con el INE, o con nosotros para que te enviemos documentación adicional. Cuenta con Classora Technologies para estar informado sobre integración, estructuración y análisis de datos.
Cada vez aparecen más noticias de grandes medios que empiezan a utilizar técnicas de periodismo robótico para automatizar la publicación de ciertas informaciones, especialmente aquéllas que dependen íntegramente de datos y que se pueden interpretar de manera objetiva.
Uno de los primeros periódicos en apostar firmemente por este tipo de tecnologías fue precisamente la Revista Forbes. Esta empresa empezó a utilizar hace tres años un software creado por científicos de la Northwestern University que le permitía cubrir cierto tipo de noticias de manera automática o semi-automática. Forbes no engaña a sus lectores y les indica en todo momento que la noticia que están visualizando es producto de un sistema inteligente que crea historias.

Periodismo robótico
El slogan de marca del robot está claro: “Nosotros transformamos datos en historias”.
Al poco de la implantación de este software, uno de los directivos de Forbes afirmaba que “los relatos son generados sin interrupciones a partir de fuentes de datos estructuradas. Pueden crearse a medida, de modo que pueden satisfacer el tono, estilo y voz esperados por el lector. Las noticias se crean en múltiples formatos, incluidos relatos largos, títulos, tweets e informes para la industria con visualizaciones gráficas. Se pueden crear múltiples versiones de una misma historia para adaptar el contenido según las necesidades específicas de cada público”.
Efectivamente, el trabajo generado por este software es mucho más barato (las compañías pagan menos de $10 por un artículo de 500 palabras) y rápido que el que pueda proporcionar un reportero convencional. Además, un robot periodista no se distrae, no está sujeto a horarios y turnos, no se queja de las condiciones de trabajo, puede analizar miles de tweets en pocos minutos e interpretar millones de datos en cortos períodos de tiempo.
Sin embargo, es completamente imposible sustituir una redacción de seres humanos por un elenco de robots. Al menos, es imposible en un periódico tradicional que aporta el valor añadido al que están acostumbrados los lectores. Las columnas de opinión, la línea editorial, la ideología subyacente, las primicias informativas, la cobertura a pie de las zonas cero… son pequeños y grandes detalles que marcarán siempre la diferencia entre unos periódicos y otros.
Por tanto, el periodismo robótico es solo otro avance que aportará ventajas a las empresas y a sus lectores, y que dejará más tiempo a los periodistas para reportajes más complejos. Reportajes de investigación basados en técnicas tradicionales o en periodismo de datos.

Esta es la filosofía con la que otra de la grandes marcas que ha apostado por el periodismo robótico, Associated Press, defiende sus productos. Lou Ferrara, coordinador de editores en esta compañía, recalca que “generar más contenido está haciendo que los suscriptores estén más contentos, ya que reciben mucha más información que antes”. Además señala que “probablemente los más escépticos pensarán que la incorporación de estos bots eliminará puestos de trabajo y que se automatizará toda la producción de noticias en una agencia. Lo cierto es que al menos de momento no es así: no se ha despedido a personal pero además, éste puede dedicar el tiempo que le ahorra el «robot generador de noticias» a trabajar en otras historias más complejas que un bot no puede realizar”.
Hace unas semanas hemos tenido que analizar, a petición de un cliente, el esfuerzo temporal y económico que supondría para nosotros la generación de un servicio que permitiera la publicación automática de noticias en español a partir de los datos publicados en fuentes estructuradas como el Instituto Nacional de Estadística, Eurostat o el Banco Mundial. Fue una grata sorpresa descubrir que, dada nuestra tecnología actual, el servicio está mucho más cerca de lo inicialmente previsto y esperamos que en breve podamos haceros partícipes de sus resultados.
Como en otras ocasiones, si te interesa conocer más información sobre este tema no dudes en contactar con nosotros para que te enviemos documentación adicional. Cuenta con Classora Technologies para estar informado sobre periodismo robótico y Data-Driven Journalism.
Como habíamos descrito con anterioridad, el periodismo de datos, o data-driven journalism (DDJ), es un proceso periodístico basado en el análisis y filtrado de grandes conjuntos de datos con el objetivo de generar una noticia inédita, o bien con la intención de respaldar, a través de hechos estadísticos, una serie de informaciones, hipótesis o conjeturas previas.
El periodismo de datos está ganando prestigio dentro del sector y cobrando una gran relevancia en la mayor parte de los diarios líderes. Sin embargo, hoy en día apenas existen tecnologías software que permitan automatizar las tareas de búsqueda e interpretación de datos periodísticos. Por ejemplo, la siguiente gráfica pone en relieve un problema social que puede ilustrar una noticia de actualidad o generar un nuevo contenido de estudio:

En este sentido, la herramienta de enriquecimiento de contenidos de Classora Technologies ha evolucionado hasta permitir dar soporte a los redactores interesados en profundizar en datos. Al igual que los servicios de etiquetado o enriquecimiento, el servicio de periodismo de datos se integra rápidamente como un botón más dentro del CMS de cada periódico. Gracias a esta funcionalidad, cualquier redactor tiene acceso a un sinfín de indicadores sociales, políticos y macroeconómicos de diferentes países, autonomías y ciudades. Puede cruzar indicadores de distintas fuentes de datos, realizar comparativas gráficas, confeccionar mapas cromáticos que evidencien la información… etc.

Estos componentes visuales se pueden generar de forma rápida e intuitiva utilizando la interfaz gráfica provista por Classora. Lo bueno es que no solo sirven para contrastar informaciones, descubrir patrones o llegar a conclusiones sorprendentes. Con un simple click, el periodista puede añadir el componente al front-end, a la noticia que esté escribiendo.
A continuación dejamos un breve vídeo demostrativo que indica como se pueden conseguir los resultados incrustados en esta entrada (y otros ejemplos) con una simple navegación por la herramienta:
Como en otras ocasiones, si te interesa conocer más información sobre este tema no dudes en contactar con nosotros para que te enviemos documentación adicional. Cuenta con Classora Technologies para estar informado sobre Data Mining y Data-Driven Journalism.